Rapport de stage
Faculté de Pharmacie de Limoges - du 7 avril au 5 juin 2025
1. Présentation contextuelle du projet
Rappel du rapport de lancement
Mon stage s’est déroulé au sein de la Faculté de Pharmacie de Limoges. L’objectif principal de ce stage était le
développement d’une application web en PHP, capable de lire un tableau de données issu d’un fichier ODS (OpenDocument Spreadsheet), puis de générer automatiquement les fichiers XML nécessaires pour la création d’exercices à destination des étudiants grâce au logiciel SCENARIchain, et son modèle documentaire Topaze.
Ce modèle est utilisé pour créer des exercices interactifs destinés aux étudiants. Les fichiers XML produits définissent entièrement la structure de chaque exercice. Une fois ces fichiers importés dans SCENARIchain, la création des parcours pédagogiques devient considérablement plus rapide et moins fastidieuse qu’une saisie manuelle.
Mon rôle au cours de ce stage a donc consisté à concevoir, développer et tester cette application web afin de simplifier et d’accélérer la production d’exercices pédagogiques numériques pour les enseignants.
Présentation du logiciel SCENARIChain
À quoi sert SCENARIChain ?
SCENARIchain est une suite logicielle open-source dédiée à la conception de documents structurés à partir de modèles éditoriaux. Dans le cadre de ce projet, c’est le modèle Topaze qui est utilisé. SCENARIchain joue le rôle de parseur : il interprète des fichiers XML structurés pour générer automatiquement des contenus pédagogiques exploitables dans divers formats (SCORM, HTML, PDF…).
Ce processus permet une production efficace et cohérente de ressources pédagogiques numériques à partir de données bien organisées. Toutefois, SCENARIchain ne peut pas être utilisé seul : il requiert impérativement un modèle documentaire (comme Topaze) pour définir la logique, la structure et la sémantique des contenus à produire.
À qui s’adresse SCENARIChain ?
SCENARIchain s’adresse principalement aux enseignants, ingénieurs pédagogiques et concepteurs de
contenus e-learning. Il leur permet de créer, structurer et diffuser des ressources éducatives de manière rigoureuse et professionnelle.
Les étudiants, quant à eux, en sont les bénéficiaires finaux : ils accèdent aux parcours pédagogiques, exercices interactifs et autres contenus générés par SCENARIchain, souvent intégrés dans des plateformes LMS telles que Moodle.
Pourquoi avoir choisi SCENARIChain ?
Le choix de SCENARIchain repose sur plusieurs atouts majeurs :
- Il s’agit d’un logiciel libre, gratuit et open-source, garantissant une certaine stabilité, une transparence du code et la possibilité de l’adapter selon les besoins.
- Il est compatible avec les standards du e-learning, notamment le format SCORM, facilitant son intégration dans les LMS existants.
- Il permet une séparation stricte entre le fond et la forme, ce qui favorise la réutilisation des contenus dans différents contextes.
- Il offre la possibilité de créer des contenus conditionnels, adaptatifs et riches, renforçant l’interactivité et l’engagement pédagogique.
Ce choix a également été dicté par les besoins et l'expérience de mon maître de stage, qui utilise SCENARI depuis plusieurs années. À noter qu’à ce jour, il n’existe pas d’outil équivalent qui combine autant de fonctionnalités de manière aussi structurée et ouverte.
Le modèle documentaire Topaze
Un modèle complet et performant
Topaze est, dans notre cas, le modèle documentaire utilisé dans SCENARIchain pour concevoir des exercices interactifs complexes. Sa particularité est sa
structure non linéaire, organisée en branches conditionnelles, ce qui permet de proposer des parcours différenciés selon les réponses ou les performances de l’utilisateur.
Ce modèle permet l’intégration de multiples éléments : pages de présentation, quiz, variables, indicateurs, etc. Il constitue un puissant outil de création pédagogique.
Topaze est en réalité une évolution du modèle Opale, avec lequel il partage une base technique similaire. Toutefois, alors qu’Opale impose un déroulé linéaire, Topaze se distingue par sa
flexibilité narrative, particulièrement adaptée aux scénarios d’apprentissage différencié ou adaptatif.
Caractéristiques principales
Parmi les fonctionnalités avancées de Topaze, on peut citer :
- Une navigation conditionnelle, adaptée au profil ou aux résultats de l’utilisateur..
- Une structuration rigoureuse du contenu : énoncés, réponses, rétroactions (feedbacks), etc.
- L’utilisation de variables et d’indicateurs dynamiques, pouvant éventuellement contenir du code JavaScript pour enrichir les interactions.
Ces éléments sont représentés dans SCENARIchain via des fichiers XML spécifiques, comme des fichiers .node (étapes de contenus) ou encore
.ind(variables et indicateurs).
Adaptation du modèle documentaire
Le comportement de Topaze peut être personnalisé, notamment via des modifications du fichier JavaScript principal,
skin.js. Cela permet par exemple d’ajouter des fonctions de calculs statistiques (comme dans notre cas), mais aussi toute autre fonctionnalité JavaScript nécessaire. Il est possible de modifier uniquement l’aspect visuel (les fichiers CSS) du modèle sans changer son fonctionnement. Cela reste néanmoins un processus nécessitant l’utilisation d’un autre modèle nommé SCENARIstyler. Dans le cadre de ce stage, seules des modifications fonctionnelles ont été apportées via le fichier skin.js ; aucune personnalisation graphique du modèle n’a été effectuée.
Cependant, toute modification plus complexe du modèle Topaze nécessite une
recompilation complète via l’outil SCENARIbuilder. La procédure consiste à :
- Télécharger les sources du modèle depuis le site officiel de SCENARI.
- Modifier les fichiers nécessaires (JS, CSS, etc.).
- Compiler une nouvelle version utilisable dans SCENARIchain.
Le fichier skin.js
Le fichier skin.js est un script JavaScript intégré au modèle documentaire Topaze. Par défaut, ce fichier est vide. Il est destiné à recevoir des fonctions personnalisées, utilisées dans les contenus générés par SCENARIchain.
Dans notre projet, ce fichier a été utilisé pour intégrer des fonctions de calcul statistique (moyenne, écart-type, etc.). Grâce à cela, les fichiers XML générés sont entièrement dynamiques, sans aucune donnée codée en dur, ce qui améliore leur réutilisabilité et facilite la création de nouveaux exercices.
Vous pouvez télécharger le fichier
skin.js
en cliquant sur ce lien.
Compilation du modèle
Pour intégrer le fichier skin.js modifié, nous avons choisi de recompiler le modèle Topaze à l’aide de SCENARIbuilder, ce qui nécessitait donc nécessaire d'avoir accès aux sources complètes du modèle. C’est seulement après l'installation du modèle personnalisé dans l'atelier de SCENARichain que les changements seront pris en compte dans SCENARIchain.
Fonctions JavaScript pertinentes
Le fichier skin.js peut contenir des fonctions JavaScript variées, telles que :
- Des calculs statistiques : moyenne, médiane, variance, écart-type…
- Des fonctions de manipulation de tableaux ou de valeurs.
- Des opérations conditionnelles dynamiques en fonction du score ou du parcours de l’utilisateur.
Ces fonctions sont ensuite appelées dans les pages du modèle via les balises XML correspondantes.
Par exemple, la fonction
calculateFrequencies permet de calculer les résultats statistiques à partir d'un tableau de données, et retourne sous forme de tableau les valeurs calculées. La deuxième capture d'écran montre l'appel à cette fonction dans un fichier XML pour le calcul des centres de classes.
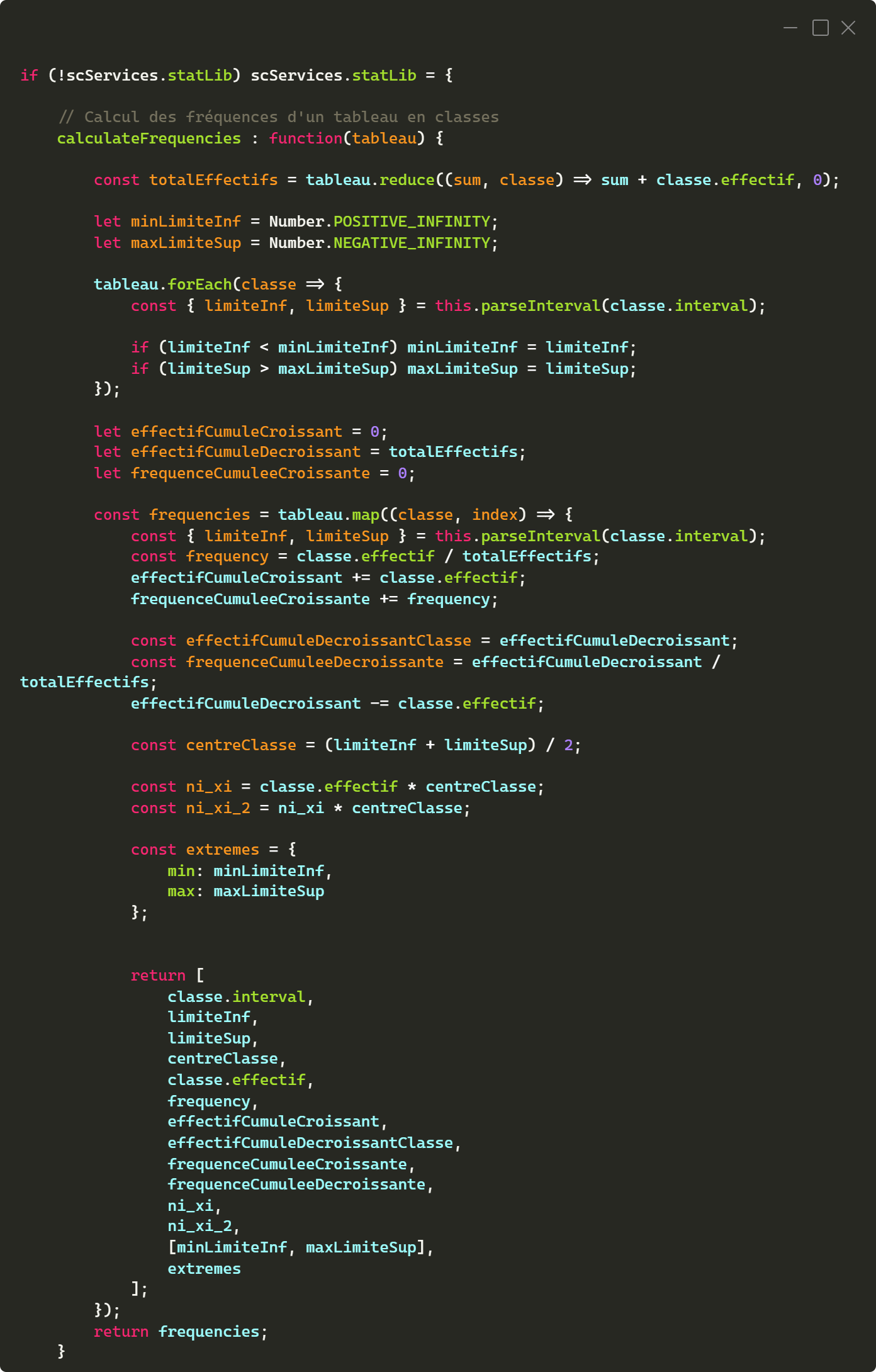 Fonction calculateFrequencies contenue dans le fichier skin.js
Fonction calculateFrequencies contenue dans le fichier skin.js
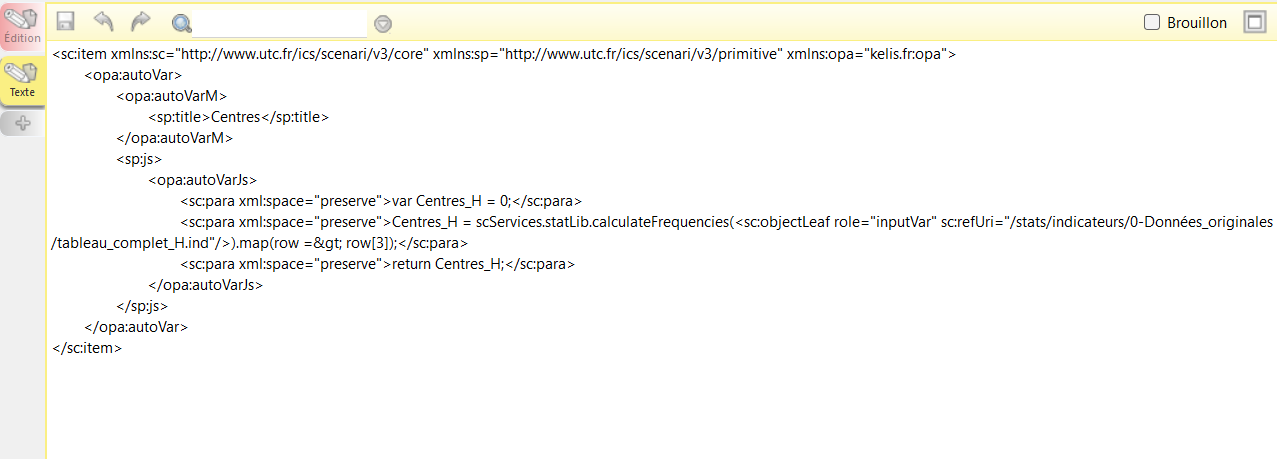 Appel à la fonction calculateFrequencies du skin.js dans un indicateur XML
Appel à la fonction calculateFrequencies du skin.js dans un indicateur XML
Structure recommandée
Pour éviter tout conflit et garantir une compatibilité avec l’ensemble des pages générées, il est conseillé d’encapsuler les fonctions dans un namespace. Une pratique courante est la suivante :
if (!scServices.statLib) scServices.statLib = {};
Cette convention permet de déclarer un espace de nommage propre (ici statLib) sans risquer d’interférer avec d’autres scripts présents dans le modèle. En effet, le fichier
skin.js est appelé dans le <footer> de chaque page. Par conséquent, l'utilisation standard des fonctions JS du type function
calculateFrequencies(tableau) {...} ne fonctionnerait pas, car l'appel à ces dernières arriverait avant le chargement du fichier JavaScript.
Mais alors, pourquoi ne pas placer ce script dans le
<head> ?
Il pourrait sembler plus simple d’intégrer directement le JavaScript personnalisé dans le <head> des pages générées. Toutefois, cela est
fortement déconseillé par les concepteurs de SCENARIchain. En effet, une telle approche casse la modularité du modèle Topaze et peut engendrer des instabilités, voire empêcher le bon fonctionnement de certaines fonctionnalités.
2. Mes missions pendant le stage
Mon rôle dans le projet
Dans le cadre de ce stage, j’ai occupé un rôle complet de développeur, en charge de concevoir, développer et tester une application web sur mesure. Cette application avait pour objectif de faciliter la génération de fichiers XML compatibles avec le modèle Topaze de SCENARIChain, à partir d’un fichier de données au format ODS. Mon implication a couvert l’intégralité du cycle de développement, depuis l’analyse des besoins jusqu’à la validation des résultats finaux.
Le projet m’a été confié dans sa globalité, ce qui signifie que j’ai moi-même développé l’ensemble de l’application, tant sur le plan du back-end (traitement des fichiers ODS, génération de l’arborescence XML, gestion de la base de données, etc.) que sur le plan du front-end (interface utilisateur, interaction avec les fichiers générés, ergonomie générale). J’ai également conçu l'ensemble des fonctionnalités de l'application, comme l’historique des générations ou encore la visualisation interactive de l’arborescence.
Tout au long du développement, j’ai également été en charge de tester l'application, ainsi que de vérifier la conformité des fichiers générés. Cela incluait donc l’importation des fichiers XML générés dans SCENARIChain afin de vérifier leur bon fonctionnement avec le modèle Topaze. Ces tests m’ont permis d’identifier les éventuelles erreurs de structure ou d’encodage, et d’adapter mon code en conséquence.
Mon maître de stage m’a accompagné dans la structuration du projet en me conseillant sur les grandes étapes à suivre, et en me fournissant un cadre fonctionnel clair. Toutefois, la mise en œuvre technique, la conception des fonctionnalités, l’organisation du code, ainsi que les choix de structure et d’architecture de l’application ont été entièrement réalisés par mes soins.
Cette autonomie dans la réalisation du projet m’a permis de développer mes compétences en développement web, en manipulation de données, et en gestion de projet, tout en répondant à des besoins concrets d’un environnement professionnel réel.
Description de l'application : SCENARI-GEN
L’application "SCENARI-GEN" que j’ai développée a pour objectif de générer automatiquement des fichiers XML structurés à partir d’un tableau ODS. Ces fichiers sont ensuite utilisés dans SCENARIchain avec le modèle pédagogique Topaze, pour créer des exercices interactifs.
Objectif principal :
Le but principal de cette application est de simplifier et d’automatiser le processus de création des fichiers XML, appelés aussi indicateurs, qui auparavant devait être effectué manuellement. Ce processus manuel était non seulement long, mais aussi source d’erreurs humaines. Grâce à l'application, les utilisateurs peuvent désormais obtenir des fichiers valides, prêts à être importés dans SCENARIchain, en quelques clics et en un temps réduit.
Les exercices générés grâce à l’application sont destinés aux étudiants. Ils ont pour but de leur permettre de manipuler des données brutes issues d’un tableau, et d’en extraire différentes informations statistiques telles que la moyenne, la médiane, les effectifs cumulés croissants, les fréquences, ou encore l’étendue. Ces exercices sont pensés pour développer la capacité des étudiants à analyser un jeu de données, à effectuer des calculs pertinents, et à interpréter les résultats obtenus dans un contexte donné. L’interactivité des exercices favorise un apprentissage actif, en sollicitant directement l’étudiant sur ses connaissances et sa capacité à les appliquer à partir de données réelles ou simulées.
Rôle de l'application dans la génération des exercices :
L’application développée a pour rôle de simplifier et d’automatiser la création de ces exercices. Elle commence par lire un tableau de données initiales, contenu dans un fichier ODS. Ce tableau représente les données de base à partir desquelles les questions seront construites. À partir de ces valeurs, l’application va générer automatiquement l’ensemble des fichiers XML (indicateurs) nécessaires pour composer l’exercice dans SCENARIchain. Cette génération inclut notamment :
- Les indicateurs de données originales :
- Ces fichiers XML contiennent les valeurs extraites directement du tableau ODS. Ils constituent la base de données de l'exercice. Ce sont les seuls fichiers générés dont les données sont inscrites en dur dans le code, sans passer par des fonctions de calcul. Ils servent de référence pour les calculs ultérieurs effectués par l’application.
- Les indicateurs de calculs initiaux :
- Ces fichiers correspondent aux résultats attendus par l’apprenant. Les valeurs qu’ils contiennent sont calculées automatiquement à l’aide des fonctions définies dans le fichier
skin.js, en se basant sur les données originales extraites du tableau ODS. Ils définissent ainsi les résultats que l’étudiant est censé obtenir s’il effectue correctement les calculs demandés dans l’exercice. - Les indicateurs de saisie :
- Les indicateurs de saisie permettent à l’étudiant de renseigner des valeurs dans l’exercice. Il s’agit de fichiers XML générés pour chaque champ dans lequel l’utilisateur peut saisir une valeur, généralement un résultat statistique qu'il a lui-même calculé.
- Les indicateurs de résultat :
- Ces fichiers servent à comparer la réponse saisie par l’étudiant avec la valeur correcte attendue. Ils établissent un lien entre l’indicateur de saisie et la valeur de référence provenant des indicateurs de calcul initiaux, en utilisant une comparaison pour déterminer si la réponse est exacte ou non.
- Les indicateurs de score :
- Les indicateurs de score sont utilisés pour attribuer un nombre de points à l’étudiant en fonction de la justesse de sa réponse. Ils s’appuient sur le résultat de la comparaison effectuée par les indicateurs de résultat pour calculer le score obtenu, selon une pondération définie dans l’exercice.
Grâce à cette automatisation, l’enseignant peut générer rapidement plusieurs exercices variés à partir de différents jeux de données, tout en garantissant la cohérence pédagogique et la justesse des calculs attendus.
Technologies utilisées
L'application repose principalement sur les technologies suivantes :
- PHP pour le traitement des fichiers ODS, la génération des fichiers XML et l'affichage dynamique des données générées
- HTML/CSS pour la mise en place de l’interface utilisateur
- SCSS pour une gestion plus modulable et claire du style, en particulier pour personnaliser le style de Bootstrap
- SQLite pour la base de données (historique des fichiers)
- Git pour le versioning
- Bibliothèques externes : OpenSpout pour la lecture des fichiers ODS, Bootstrap et Bootstrap Icons pour la mise en forme et Symfony Finder pour l'arborescence des fichiers interactive
Arborescence de l'application
L'application est structurée selon une logique claire et modulaire :
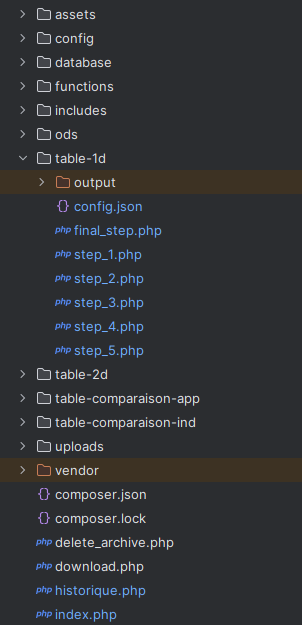 Arborescence des fichiers de l'application
Arborescence des fichiers de l'application
Fonctionnalités principales de l'application
L’application permet de générer automatiquement l’ensemble des fichiers nécessaires à la création d’un exercice interactif à destination de SCENARIchain.
Elle propose plusieurs types d’exercices basés sur des tableaux de données statistiques importés au format ODS. L’utilisateur peut choisir entre différents formats de tableaux : des tableaux à une dimension, deux dimensions, ainsi que des tableaux comparatifs basés sur deux échantillons indépendants ou appariés.
L’outil permet ensuite, via un formulaire intuitif, d’importer le fichier ODS souhaité, de sélectionner la feuille de calcul concernée, de définir la plage de cellules à analyser, ainsi que de nommer l’exercice. Une fois ces informations renseignées, le processus de génération se lance en plusieurs étapes, produisant l’ensemble des fichiers XML nécessaires : données originales, saisies, calculs, résultats et scores. Une fonctionnalité complémentaire permet à l’utilisateur de récupérer l’ensemble de ces fichiers regroupés dans une archive ZIP téléchargeable directement depuis l’interface.
Enfin, l’application intègre également un module d’historique qui enregistre les archives générées. Cette section donne la possibilité de re-télécharger un exercice produit antérieurement, ou de supprimer les archives devenues obsolètes. Cette fonctionnalité renforce l’ergonomie de l’application et facilite la gestion des ressources créées.
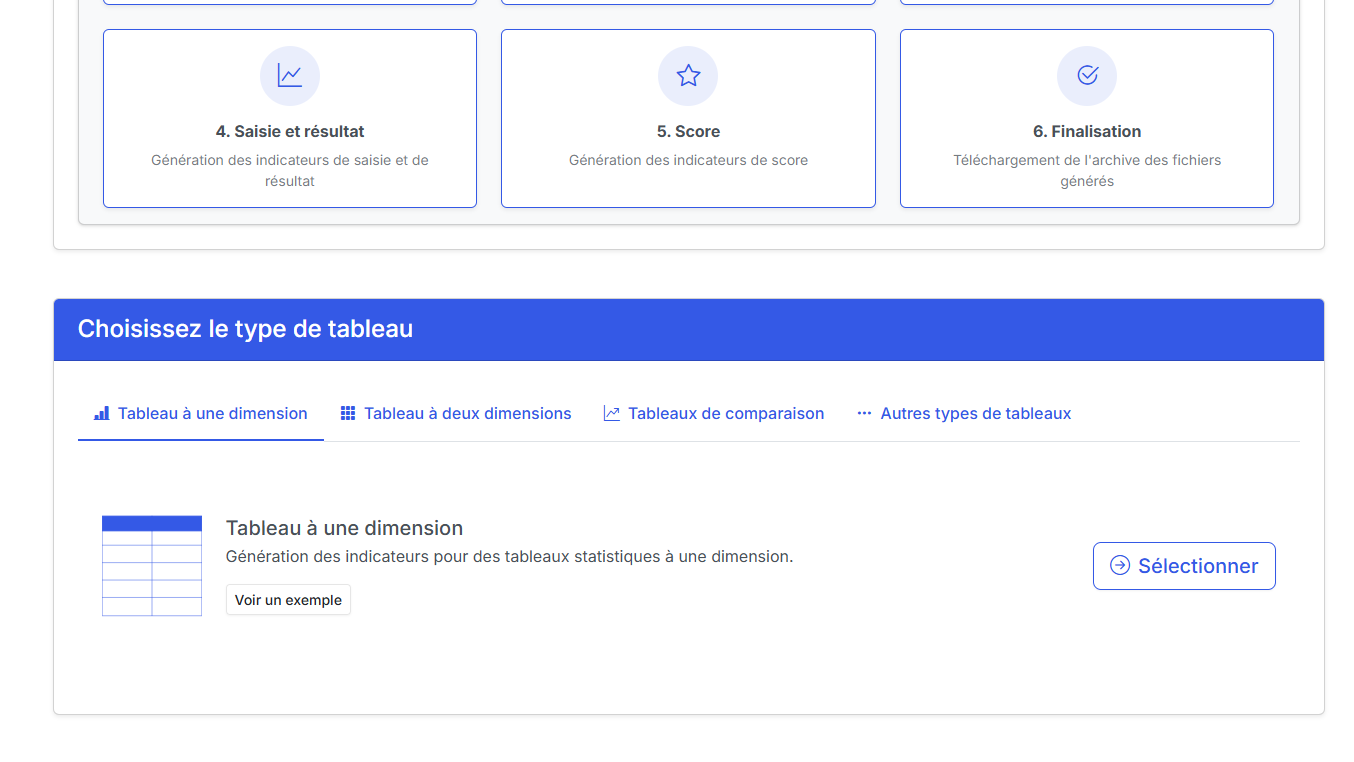 Choix du type de tableau de données à traiter sur la page d'accueil de l'application
Choix du type de tableau de données à traiter sur la page d'accueil de l'application
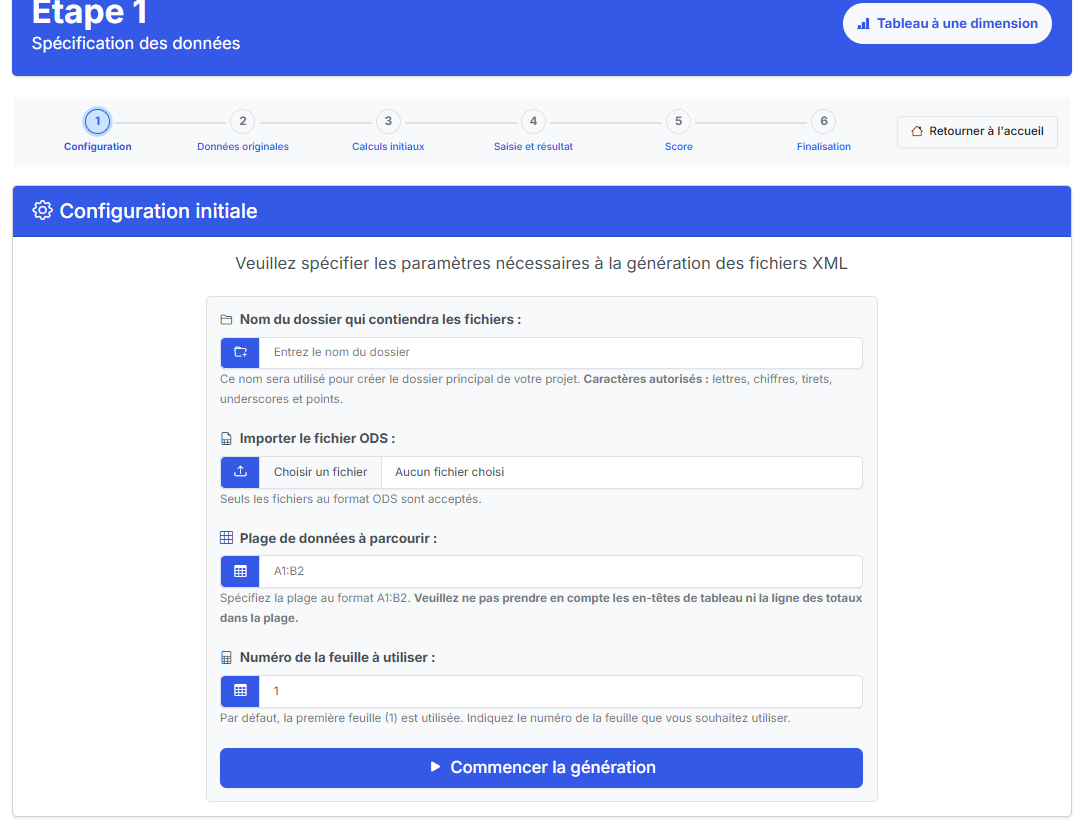 Formulaire pour remplir les informations nécessaires à la lecture du fichier ODS
Formulaire pour remplir les informations nécessaires à la lecture du fichier ODS
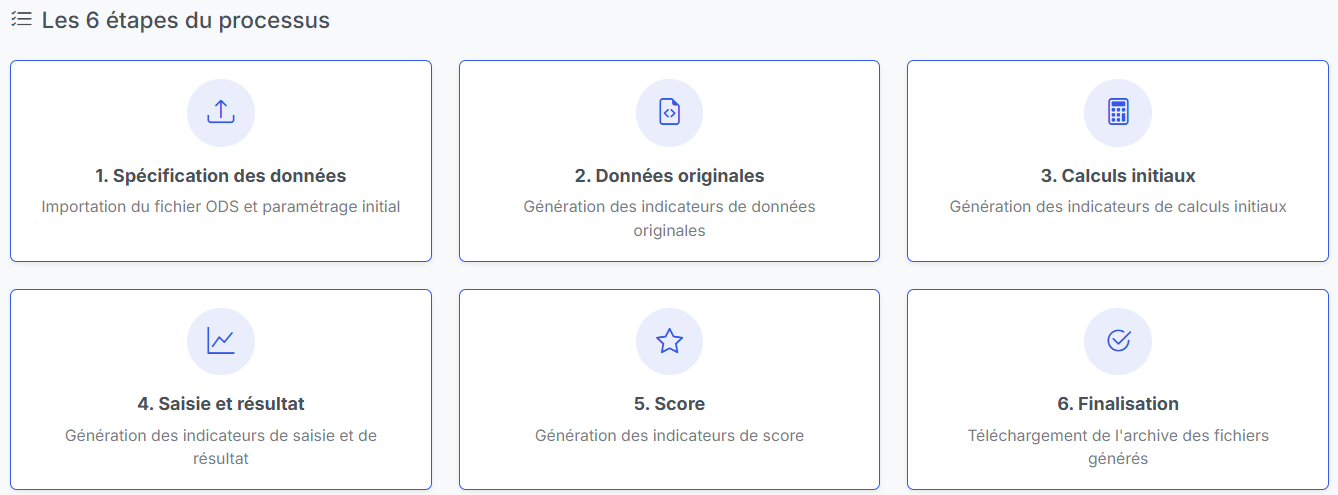 Les 6 étapes de fonctionnement de l'application
Les 6 étapes de fonctionnement de l'application
Fonction de lecture ODS
L’une des premières étapes du processus consiste à lire un tableau de données statistiques contenu dans un fichier ODS (OpenDocument Spreadsheet), fourni par l’utilisateur. Une fois le type de tableau choisi (une dimension, deux dimensions, comparatif, etc.), un formulaire est proposé. Ce formulaire permet de renseigner plusieurs
informations essentielles : le nom de l’exercice, le fichier ODS à téléverser, la feuille du classeur à utiliser, ainsi que la plage de cellules à parcourir dans le tableau. Cette plage est généralement saisie sous un format classique (par exemple A1:B2), tel qu’utilisé dans les tableurs.
Vous pouvez télécharger le fichier ODS
en cliquant sur ce lien.
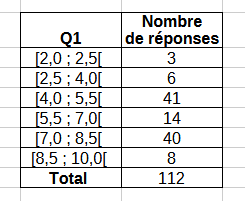 Exemple d'un tableau à une dimension
Exemple d'un tableau à une dimension
Pour pouvoir exploiter ces informations dans le traitement automatisé, il est nécessaire de convertir
cette plage textuelle en indices numériques, car la
bibliothèque OpenSpout — utilisée pour lire les fichiers ODS dans notre application — s’attend à recevoir des coordonnées numériques (indices de lignes et de colonnes). Deux fonctions spécifiques sont donc utilisées à cette fin :
convertODS() et parseODSRange(). Ces fonctions se chargent de traduire la
plage fournie en paramètres exploitables par la fonction de lecture principale. Une fois cette étape franchie, la fonction
readODSData1D() est utilisée pour lire les données du tableau à une dimension (il y a des variantes de cette fonction pour les autres types de tableaux). Cette fonction vient parcourir la plage spécifiée, ligne par ligne, et
extrait les données nécessaires. Par exemple, dans un tableau simple, la première colonne représente les classes, et la seconde les effectifs associés.
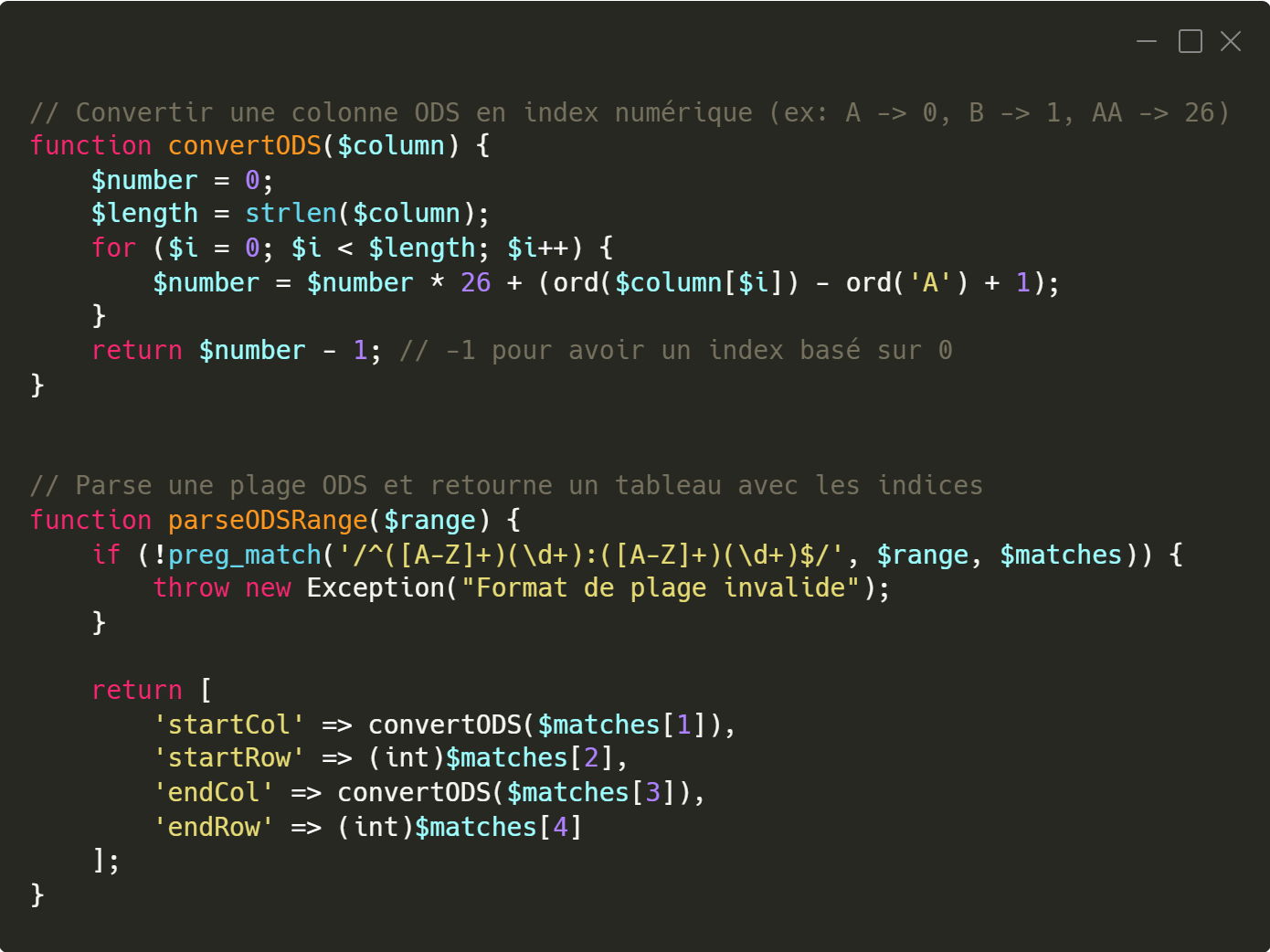 Fonction pour convertir correctement une plage ODS avant la lecture du fichier
Fonction pour convertir correctement une plage ODS avant la lecture du fichier
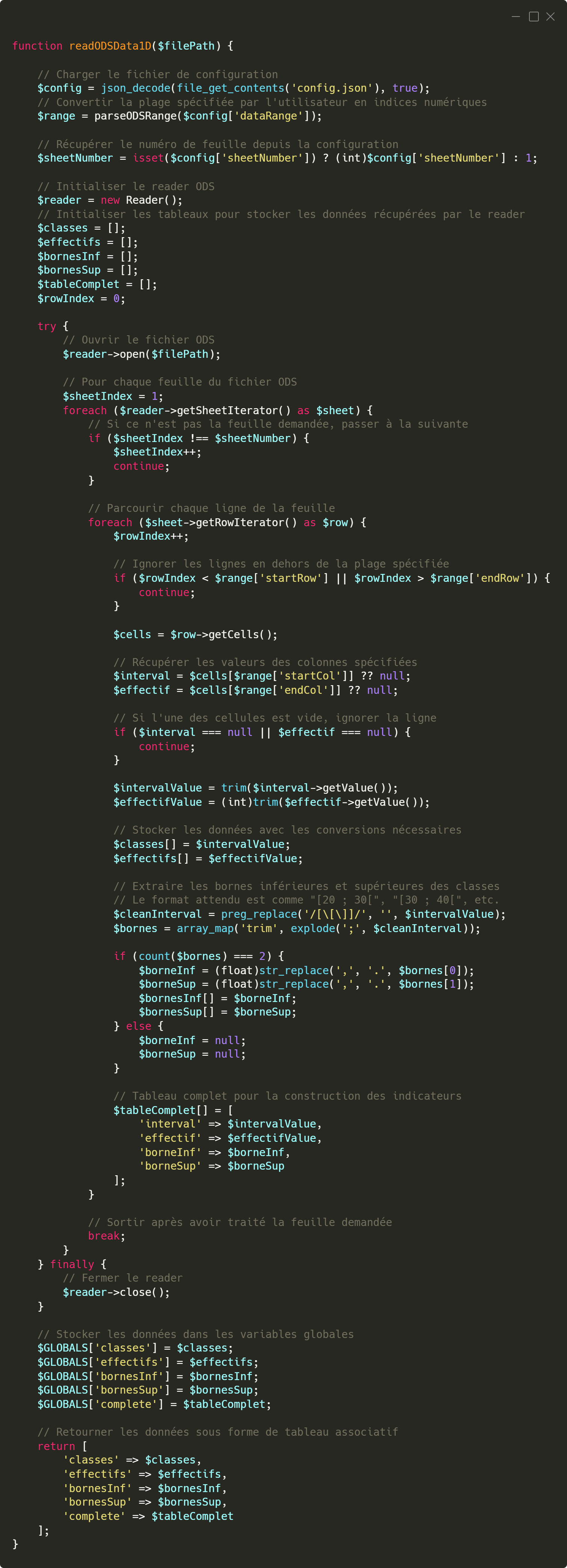 Fonction PHP pour récupérer les données contenus dans le fichier ODS
Fonction PHP pour récupérer les données contenus dans le fichier ODS
L’application est actuellement conçue pour fonctionner uniquement avec des fichiers au format ODS. Ce choix n’est pas dû à une contrainte technique, car il serait tout à fait possible d’adapter la fonction de lecture afin de prendre en charge d’autres formats courants tels que XLS ou XLSX (formats Excel). Cependant, ce choix est volontaire et motivé par les besoins spécifiques de mon maître de stage. En effet, il utilise la suite bureautique LibreOffice, dont le format de fichier natif est le ODS. Ce format libre et ouvert a donc été privilégié pour garantir une compatibilité optimale avec les outils utilisés en interne. Cela permet également de s’inscrire dans une logique de logiciels libres, en cohérence avec les valeurs et les pratiques de l’environnement professionnel dans lequel le projet a été réalisé.
Fonction de génération de fichiers XML
Une fois le formulaire rempli et validé — incluant le choix du type de tableau, le nom de l’exercice, le fichier ODS à importer, la feuille à utiliser et la plage de données à lire —, l’application procède automatiquement à la création récursive de la structure de dossiers nécessaire. Cette arborescence accueillera tous les fichiers XML générés par la suite. La première étape de traitement consiste ensuite à générer les indicateurs de données originales, qui sont les fichiers contenant les valeurs extraites directement du tableau ODS. Ces fichiers servent de base à l’ensemble des calculs réalisés dans les étapes suivantes.
Indicateurs et variables de données originales
Dans cette section, je ne détaillerai pas l’ensemble des indicateurs générés par l’application, car ils sont nombreux et souvent similaires dans leur logique de création. En revanche, je vais m’attarder sur deux d’entre eux, qui me paraissent particulièrement représentatifs du fonctionnement de l’outil.
Le premier concerne la
génération du tableau complet, qui est l’unique fichier indicateur contenant des valeurs inscrites en dur. La génération commence par l’extraction des données du fichier ODS via la fonction
readODSData1D, qui retourne les valeurs sous forme de tableau PHP. Ces données sont ensuite converties en tableau JavaScript, ce qui permet leur traitement ultérieur par les fonctions de calcul du fichier
skin.js. Après avoir défini le chemin de sortie du fichier, un appel à la fonction genAutovarXML permet de générer le fichier XML correspondant au tableau complet. Ce fichier est ensuite enregistré dans le dossier approprié, et la variable
totalFichiers, qui assure le suivi du nombre de fichiers générés, est incrémentée. Ce type de fichier est appelé, dans SCENARIchain, une
variable calculée automatiquement. Il s’agit d'une variable qui contient d'une manière générale des informations alphanumériques, mais dans d'autres cas, peut contenir un tableau de données statiques ou des appels à des fonctions JavaScript définies dans le fichier skin.js.
Le second exemple concerne la génération des fichiers de fréquences individuelles. Cette étape débute par l’initialisation de la variable
frequencesFiles, dont la valeur correspond au nombre d’éléments présents dans le tableau complet issu du fichier ODS. Dans le cas d’un tableau à une dimension, cela revient à compter le nombre de lignes, c’est-à-dire le nombre de valeurs statistiques présentes. Une boucle est ensuite utilisée pour générer un fichier de fréquence pour chaque valeur. Par exemple, si le tableau contient six lignes, l’application générera automatiquement six fichiers XML, chacun correspondant à la fréquence individuelle d’une des valeurs du tableau. Ce fonctionnement assure une précision et une personnalisation optimale dans la construction des exercices, adaptés aux données fournies. Ce type de fichier est appelé, dans SCENARIchain, un
indicateur calculé automatiquement. Il s’agit d’un indicateur qui contient une valeur numérique unique ou qui contient un appel à un autre indicateur.
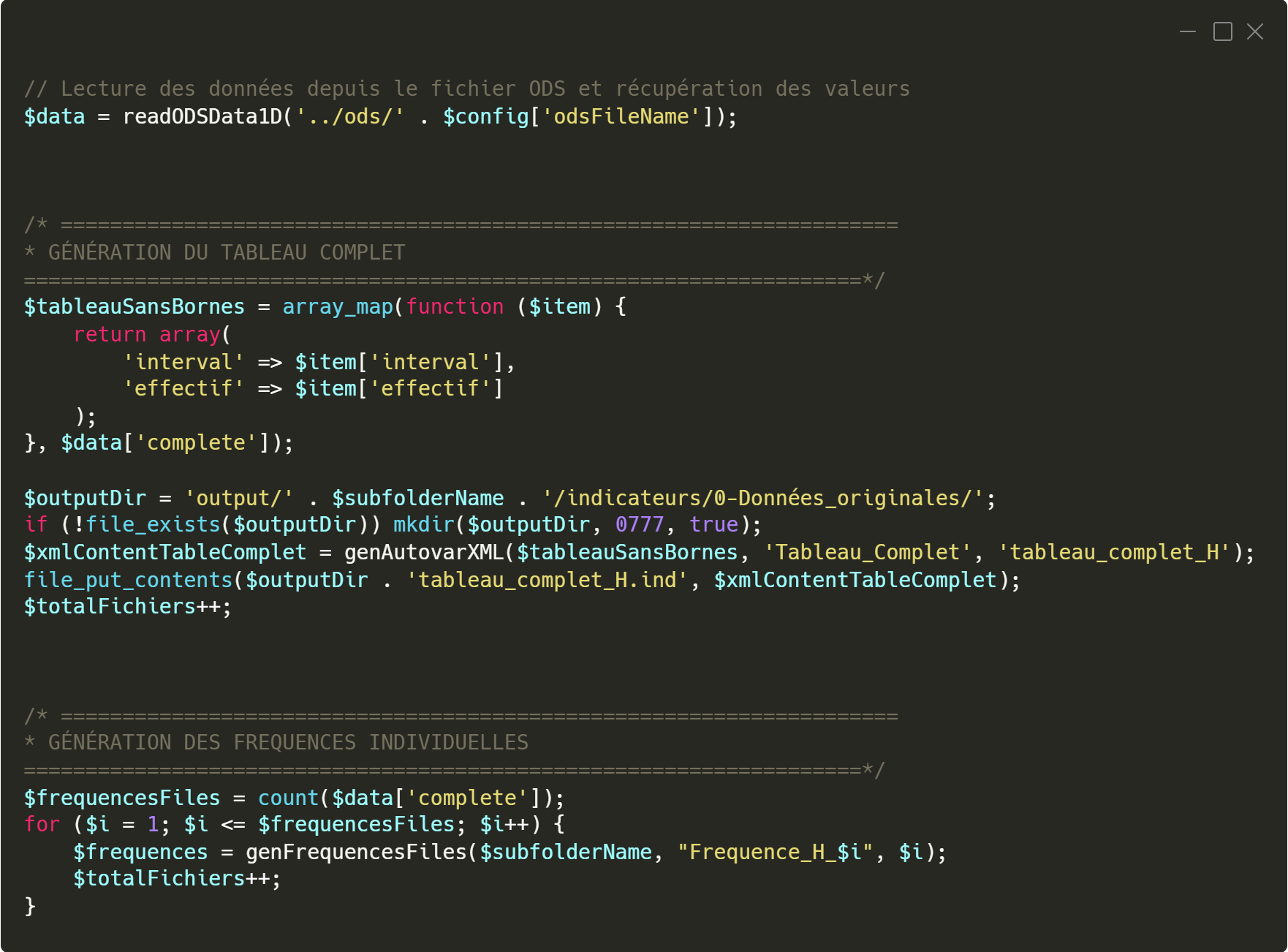 Extrait du code qui permet la génération des fichiers XML du tableau complet et des fréquences
Extrait du code qui permet la génération des fichiers XML du tableau complet et des fréquences
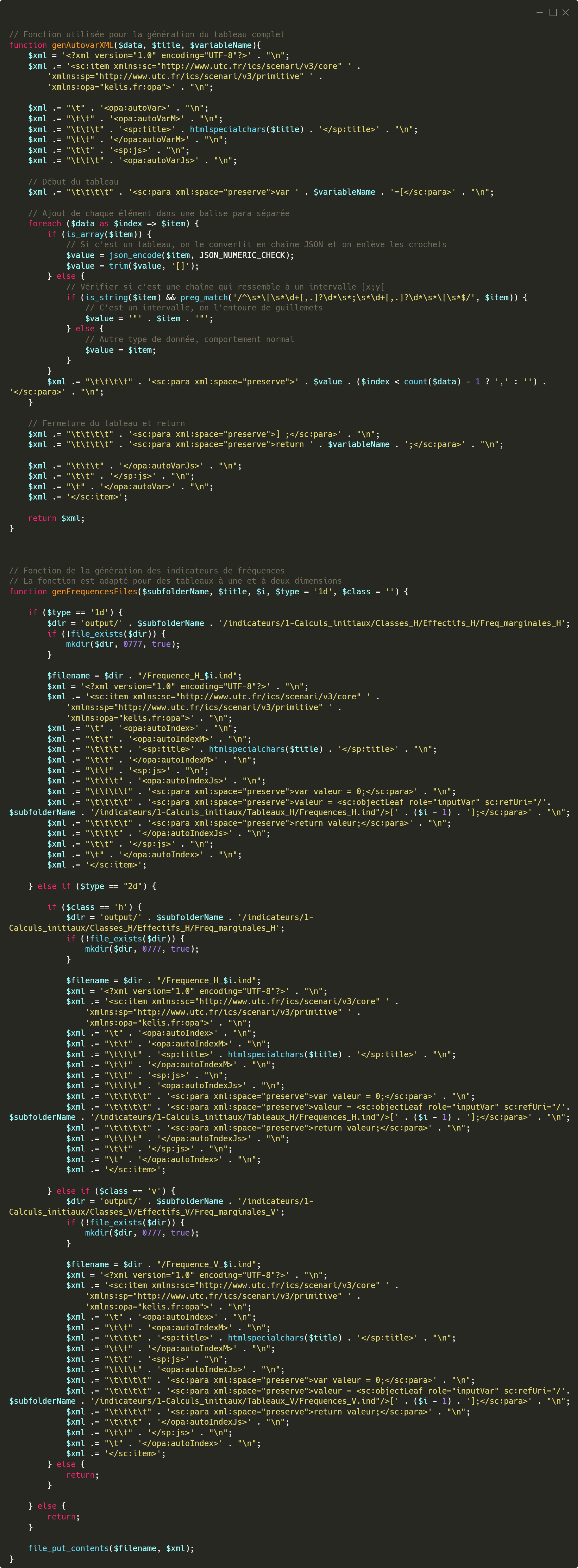 Fonctions PHP permettant la génération du tableau complet et des fréquences
Fonctions PHP permettant la génération du tableau complet et des fréquences
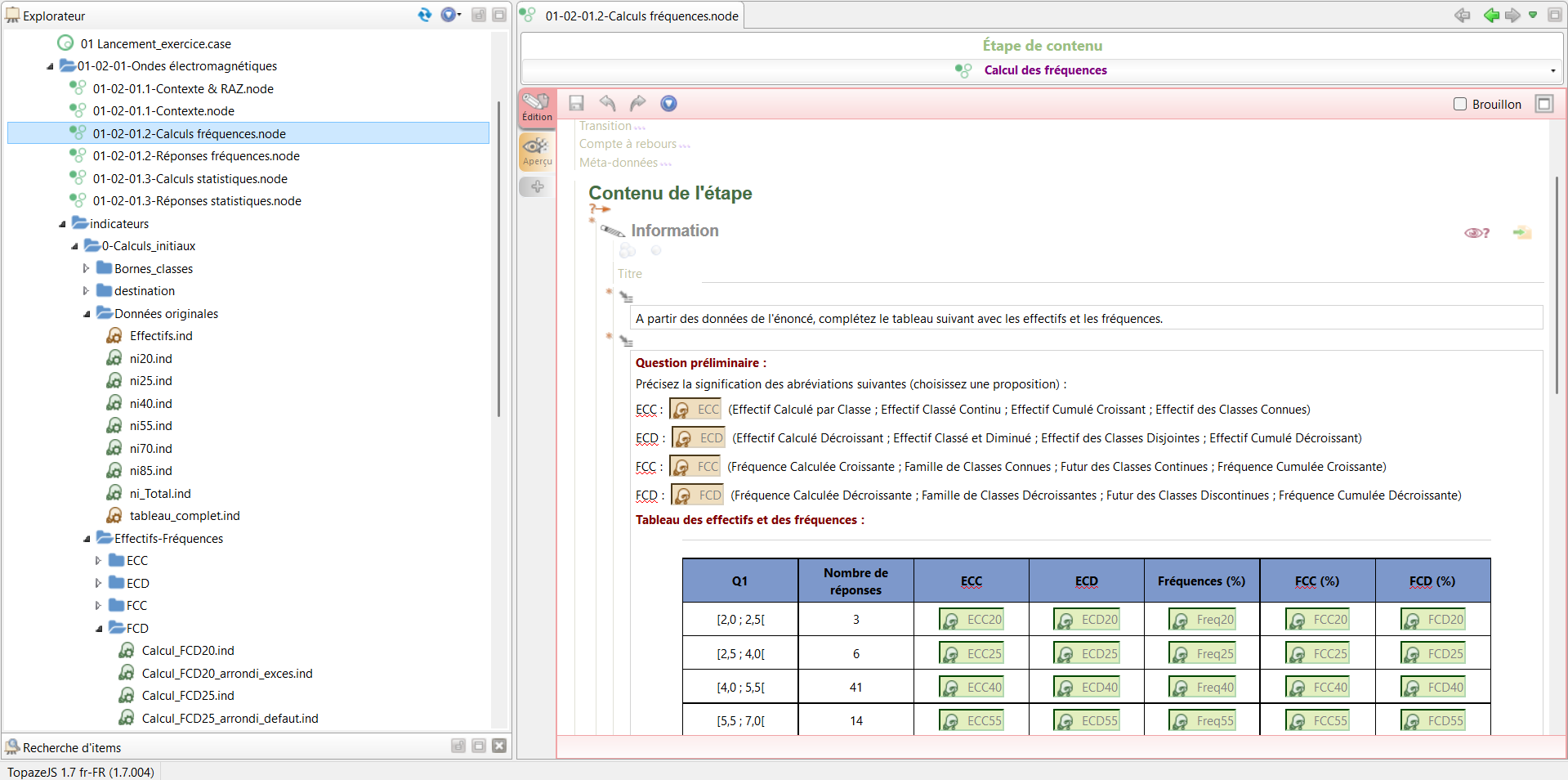
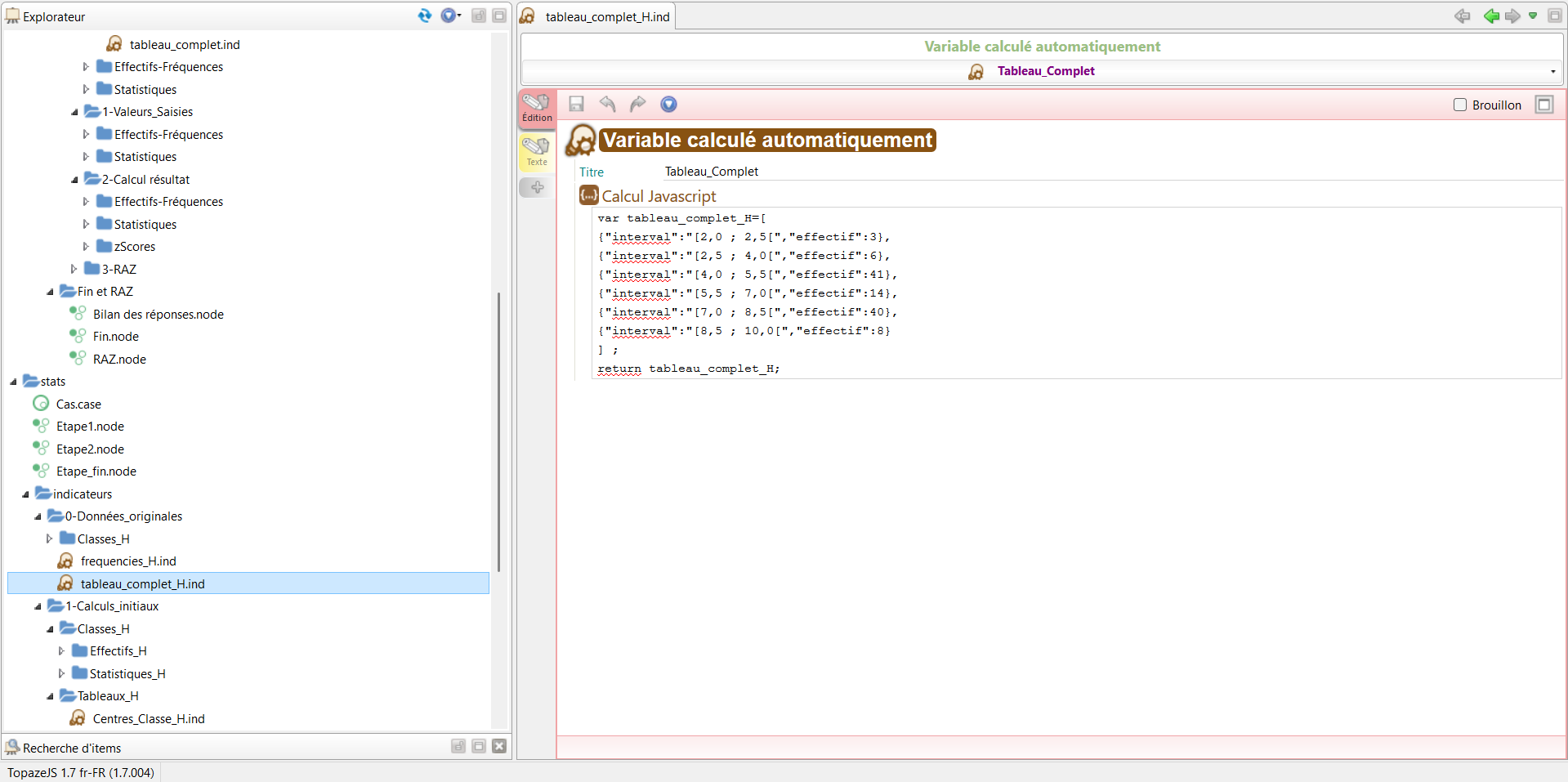
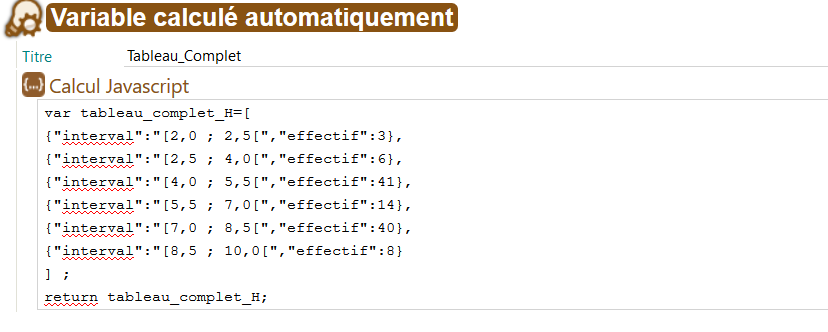 Aperçu du fichier XML du tableau complet dans SCENARIchain
Aperçu du fichier XML du tableau complet dans SCENARIchain
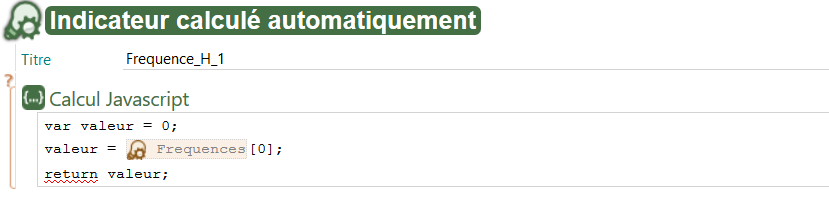 Aperçu d'un fichier XML de fréquence dans SCENARIchain
Aperçu d'un fichier XML de fréquence dans SCENARIchain
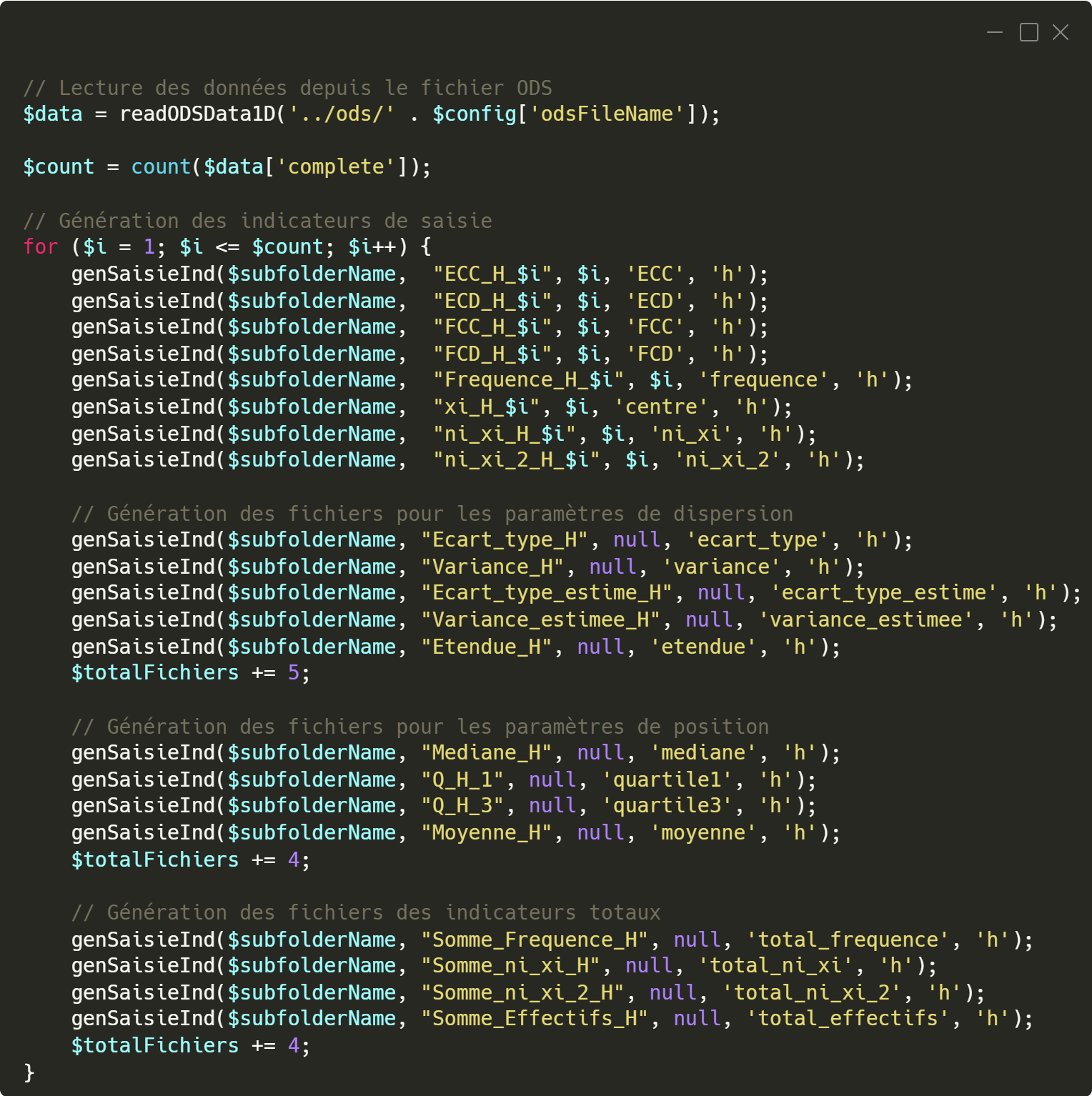
Indicateurs de calculs initiaux
La génération des indicateurs de calculs initiaux suit un procédé similaire à celui des données originales. On commence une nouvelle fois par un appel à la fonction
readODSData1D, qui permet de récupérer les valeurs du tableau statistique depuis le fichier ODS. Ces données servent ensuite à générer plusieurs types d’indicateurs destinés à guider les calculs attendus de l’étudiant, par exemple :
- Les fréquences cumulées croissantes (FCC)
- Les fréquences cumulées décroissantes (FCD)
- Les effectifs cumulés croissants (ECC)
- effectifs cumulés décroissants (ECD)
Pour chaque type d’indicateur, une boucle est utilisée afin de générer autant de fichiers que de lignes dans le tableau, comme expliqué précédemment. À chaque itération, la fonction
genEffectifs_FrequencesFiles est appelée. Cette fonction prend plusieurs paramètres : le nom du sous-dossier défini par l’utilisateur, le titre du fichier à générer, l’indice i de la boucle (qui correspond à la ligne traitée), le type d’indicateur à créer (ECC, ECD, FCC ou FCD), et enfin une classe. Cette classe permet de différencier les tableaux horizontaux et verticaux (tableaux 1D et 2D) ; elle est généralement de la forme H ou Hx pour un tableau horizontal, ou simplement V pour un tableau vertical. Dans notre exemple, la classe est de type H, car il s’agit d’un tableau à une dimension. Grâce à cette logique, l’application peut générer automatiquement l’ensemble des fichiers correspondant aux calculs statistiques de base attendus dans les exercices.
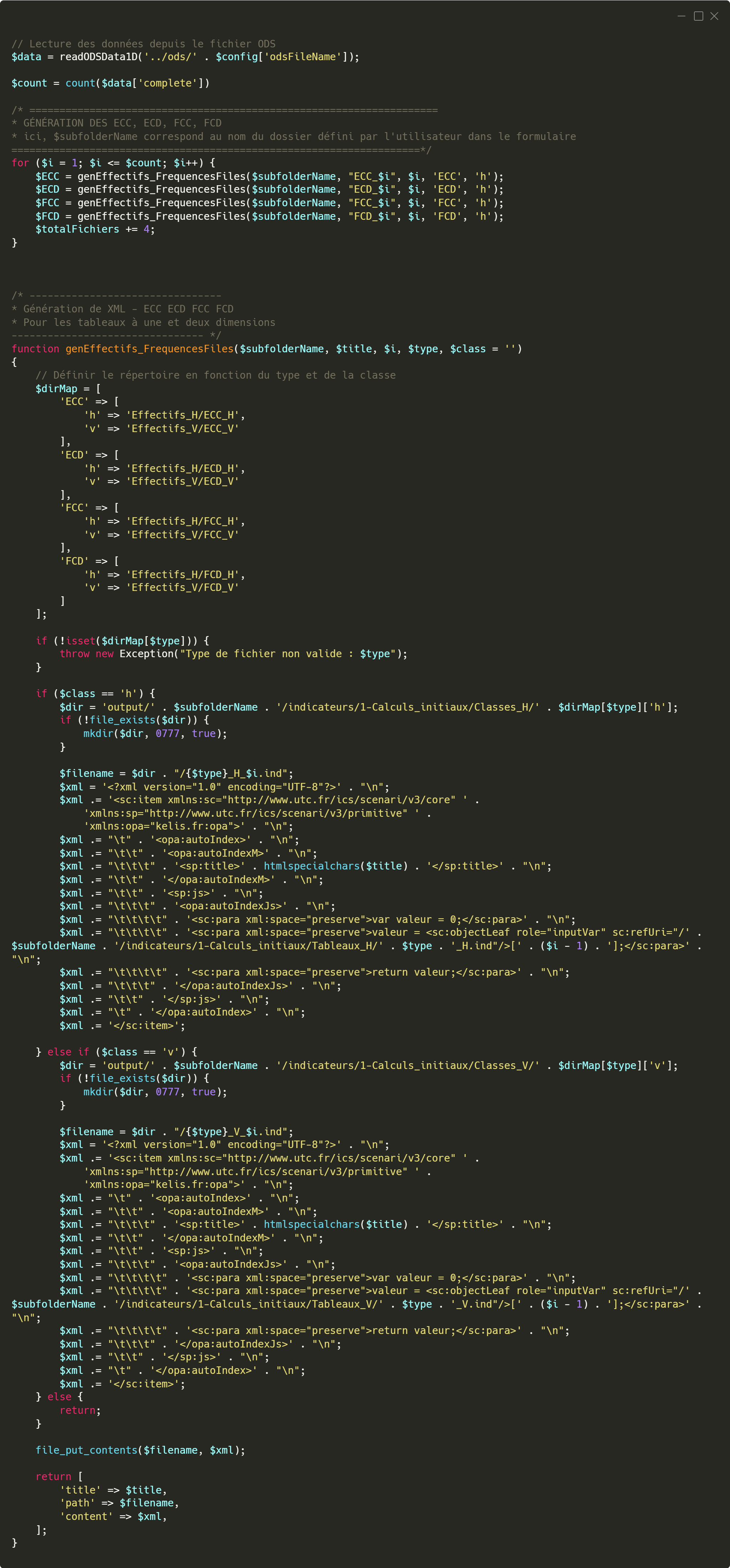 Extrait du code qui permet la génération des fichiers XML des ECC, ECD, FCC et FCD
Extrait du code qui permet la génération des fichiers XML des ECC, ECD, FCC et FCD
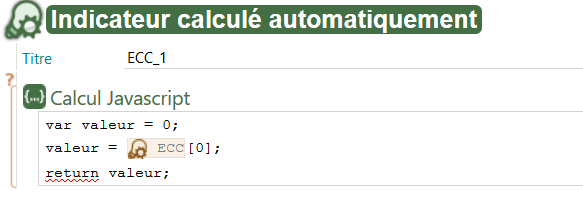 Aperçu du fichier XML d'un ECC dans SCENARIchain
Aperçu du fichier XML d'un ECC dans SCENARIchain
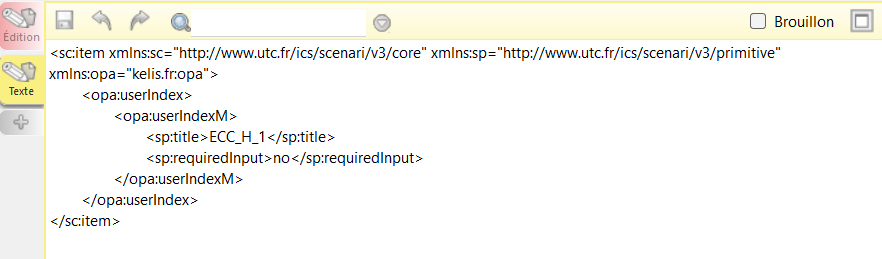
Indicateurs de saisie
Les indicateurs de saisie sont des indicateurs de type apprenant. Ces fichiers XML permettent, une fois l’exercice compilé avec SCENARIchain, d’autoriser l’utilisateur à
saisir une valeur en réponse à une question. Leur construction repose sur le même principe que les indicateurs calculés : une boucle détermine combien de fichiers doivent être générés en fonction des données du tableau. Chaque fichier de saisie contient essentiellement deux paramètres : un titre, qui décrit la valeur attendue, et un champ
requiredInput défini à « yes » ou « no », selon que la saisie est obligatoire ou non. Dans notre cas, nous choisissons de ne pas rendre la saisie obligatoire, afin de ne pas bloquer les étudiants dans leur progression s’ils ne parviennent pas à répondre à certaines questions.
 Extrait du code qui permet la génération des indicateurs de saisie
Extrait du code qui permet la génération des indicateurs de saisie
 Fonction qui permet la génération de tous les indicateurs de saisie
Fonction qui permet la génération de tous les indicateurs de saisie
 Aperçu du fichier XML de saisie pour le premier ECC dans SCENARIchain
Aperçu du fichier XML de saisie pour le premier ECC dans SCENARIchain
Indicateurs de résultat
Les indicateurs de résultat jouent un rôle essentiel dans l’évaluation de l’apprenant, en calculant
automatiquement les points obtenus en fonction de ses réponses. On distingue deux types d’indicateurs générés à cette étape : les indicateurs calculés automatiquement, qui retournent une
valeur numérique 0 (faux) ou 1 (juste), et les variables calculées automatiquement, retournant le résultat
en clair avec une coche validée quand le résultat est juste. Le principe repose sur une comparaison entre la valeur saisie par l’étudiant et la valeur calculée attendue.
Par exemple, pour le premier effectif cumulé croissant (ECC_1), l’indicateur de résultat va d’abord récupérer la valeur saisie via un lien vers l’indicateur de saisie correspondant, puis la valeur calculée initialement via un lien vers l’indicateur de calcul. Une condition if vient ensuite vérifier l’égalité entre les deux valeurs. Si elles sont identiques, un point est attribué (retour de 1). Enfin, tous les points individuels sont agrégés par des indicateurs de score, qui additionnent les valeurs retournées pour calculer le score total de l’étudiant.
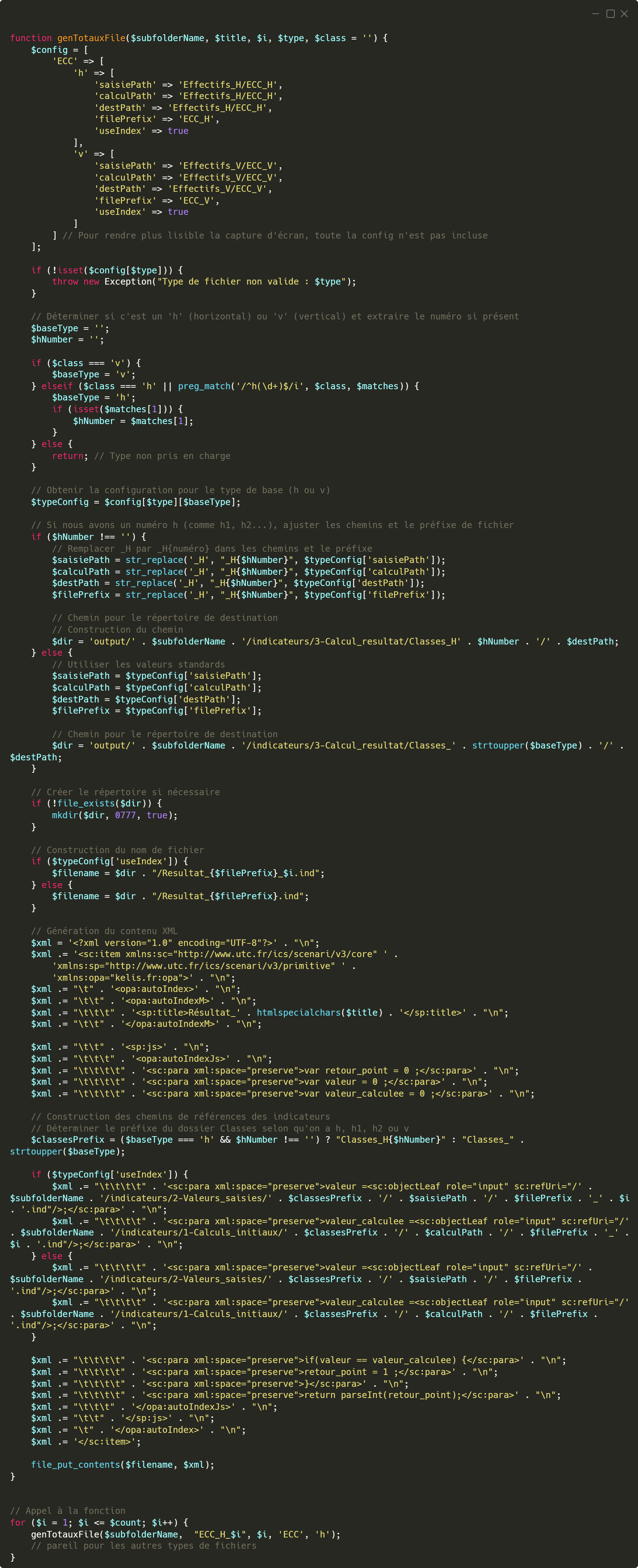 Fonction qui permet la génération des indicateurs de résultat
Fonction qui permet la génération des indicateurs de résultat
 Aperçu du fichier XML de résultat numérique pour le premier ECC dans SCENARIchain
Aperçu du fichier XML de résultat numérique pour le premier ECC dans SCENARIchain
 Aperçu du fichier XML de résultat textuel pour le premier ECC dans SCENARIchain
Aperçu du fichier XML de résultat textuel pour le premier ECC dans SCENARIchain
L'application est désormais mise en ligne, il est possible de la tester en cliquant sur le bouton ci-dessous.
Consulter l'application
Le code source de l'application est également consultable sur le repository GitHub en cliquant sur
ce lien.
3. Planning du travail réalisé
Afin d’assurer une gestion efficace du projet tout au long de mon stage, j’ai mis en place plusieurs outils de planification et de suivi des tâches. Dès la rédaction du rapport de lancement, un
planning prévisionnel a été établi sous forme de
tableau. Celui-ci avait pour objectif de définir les grandes étapes du projet, d'en estimer la durée et
d'en anticiper les différentes phases de réalisation.
Cependant, un planning prévisionnel ne suffit pas à lui seul pour suivre précisément l’avancement du travail. C’est pourquoi, tout au long de mon stage, j’ai tenu à jour un diagramme de Gantt interactif que j’ai conçu sur la plateforme Notion. Ce diagramme m’a permis de
visualiser en temps réel les différentes tâches à accomplir, celles en cours de réalisation, celles en retard ou encore celles déjà terminées. Ce mode de représentation m’a aidé à mieux répartir mon temps, à hiérarchiser les priorités et à ajuster l’organisation du travail en fonction des imprévus ou des évolutions du projet.
Par rapport au planning prévisionnel, le développement de la prise en charge des tableaux à deux dimensions a connu un léger retard. Bien que modeste, ce décalage a eu un effet domino sur les tâches suivantes. Toutefois, ce retard a rapidement été compensé, ce qui a permis de préserver l’avancement global du projet sans impact significatif.
En complément du diagramme de Gantt, Notion propose également une vue en tableau, qui offre une lecture synthétique de toutes les tâches sous forme de liste, avec des informations comme l’état d’avancement, les échéances ou les commentaires associés.
4. Analyse du travail réalisé
Points forts
Le développement de l’application web au cours de ce stage a permis de répondre efficacement aux besoins identifiés en amont du projet. Plusieurs points forts ressortent du travail accompli, tant sur le plan technique que fonctionnel :
- Simplicité d'utilisation :
- L’application a été pensée pour être intuitive et accessible aux utilisateurs non-développeurs. L’interface claire et les étapes guidées permettent une prise en main rapide par les enseignants, sans nécessiter de connaissances techniques avancées.
- Gain de temps considérable :
- L’un des objectifs majeurs du projet était de réduire le temps nécessaire à la création des fichiers XML utilisés dans SCENARIChain. Cet objectif a été largement atteint : là où la création d’un exercice simple (comme l’exercice 1) nécessitait auparavant une journée entière de travail manuel, l’application permet désormais de générer les fichiers correspondants en moins d’une minute, de manière automatique. Ce gain de temps significatif libère l'utilisateur pour se concentrer davantage sur le contenu pédagogique.
- Ergonomie et visualisation claire :
- Une attention particulière a été portée à l’ergonomie de l’interface. En plus de la simplicité d’utilisation, l’application propose des fonctionnalités de visualisation interactive, comme l’arborescence des fichiers générés ou encore les statistiques de production. Ces éléments facilitent le suivi du travail effectué et offrent une meilleure compréhension de la structure du contenu généré.
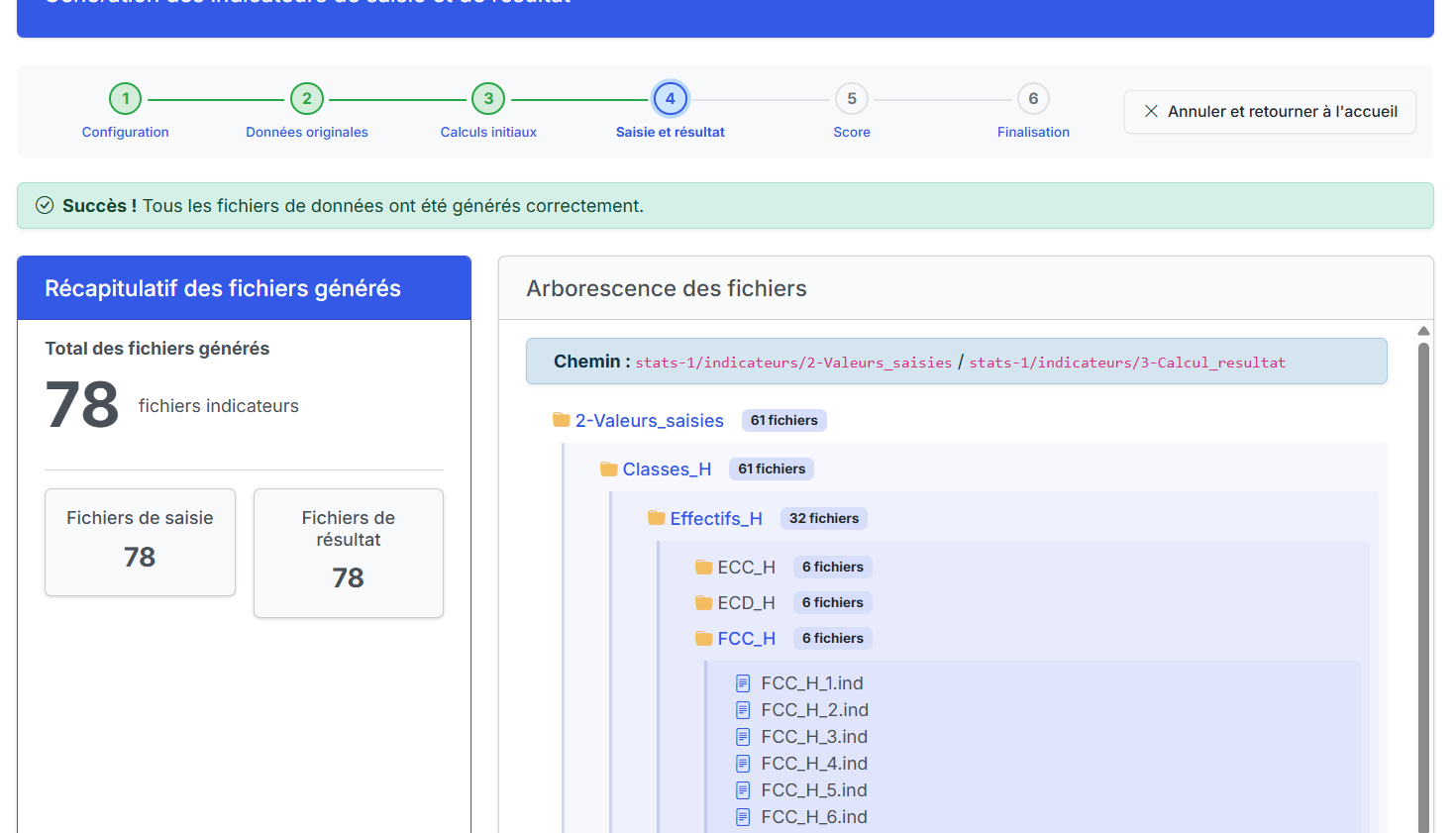 L'interface de l'application affiche les fichiers générés dans une arborescence interactive
L'interface de l'application affiche les fichiers générés dans une arborescence interactive
- Fonctionnalités pratiques intégrées :
- Pour améliorer l’expérience utilisateur, des fonctionnalités complémentaires ont été ajoutées, comme l’historique des fichiers générés, permettant de retrouver rapidement un travail antérieur ou de restaurer une version précédente. Cela renforce la fiabilité de l’outil tout en offrant une flexibilité accrue.
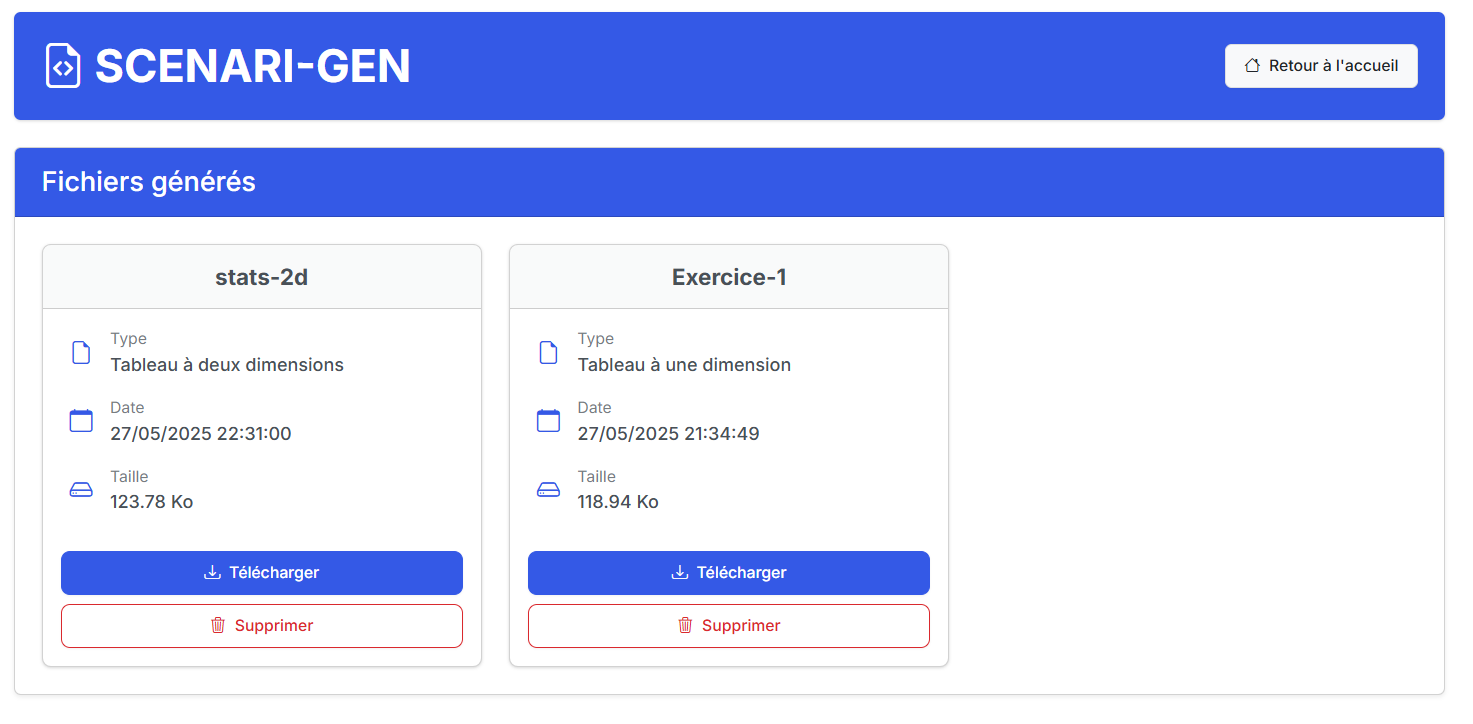 L'historique offre la possibilité de retélécharger les fichiers précédemment générés, ainsi que de les supprimer de la base de données
L'historique offre la possibilité de retélécharger les fichiers précédemment générés, ainsi que de les supprimer de la base de données
Points d'améliorations
Bien que l’application réponde efficacement aux objectifs fixés et qu’elle ait apporté des résultats concrets et satisfaisants, plusieurs pistes d’amélioration ont été identifiées au cours du développement. Ces évolutions pourraient permettre d’enrichir l’outil, de le rendre plus robuste et plus adaptable à l’avenir :
- Rendre l’application plus générique :
- Actuellement, l’application repose sur une structure de tableau et une organisation de contenu relativement spécifiques. Il serait pertinent de la rendre plus générique, de façon à ce qu’elle puisse fonctionner avec des fichiers ODS présentant des structures différentes, voire avec d’autres formats de données. Cela permettrait d’élargir les cas d’usage et de répondre à des besoins plus variés.
- Dynamiser davantage la gestion des chemins et des noms :
- Le système actuel repose encore partiellement sur des chemins de fichiers, noms de dossiers ou noms de fichiers définis de manière statique. Une amélioration consisterait à gérer dynamiquement ces paramètres, soit via une interface de configuration, soit à l’aide d’un système d’options adaptables à chaque projet. Cela renforcerait la flexibilité de l’outil, en le rendant plus facilement utilisable dans des environnements différents.
- Refonte en programmation orientée objet :
- Le code de l’application a été conçu en procédural, ce qui reste efficace dans le cadre d’un projet unique et maîtrisé. Néanmoins, une refonte en programmation orientée objet (POO) permettrait de structurer plus clairement le code, de le rendre plus maintenable et évolutif, notamment en vue de futurs ajouts de fonctionnalités ou de l’ouverture à d’autres utilisateurs développeurs.
- Génération automatique des étapes de contenu (fichiers .node) :
- Une des évolutions majeures possibles serait de permettre la génération
automatique des fichiers
.node, qui représentent les étapes pédagogiques dans un parcours Topaze (par exemple, les pages de questions). Actuellement, cette génération est absente, limitant le potentiel de création complète d’un exercice interactif. L’intégration de cette fonctionnalité rendrait l’outil encore plus utile dans la création de parcours pédagogiques complexes.
Actions correctives
Au cours de l’utilisation de l’application, certaines anomalies ont été identifiées, nécessitant des corrections pour garantir une stabilité optimale et une fiabilité totale du système. Ces problèmes sont relativement ciblés, mais peuvent impacter la qualité du résultat final s’ils ne sont pas corrigés.
- Correction de la fonction de lecture des fichiers ODS :
- Pour certains types de tableaux, la fonction chargée de lire les fichiers ODS rencontre des difficultés à respecter la plage de données spécifiée. Il peut en effet arriver que la lecture déborde en amont ou en aval de la plage attendue, ce qui peut entraîner des erreurs dans le traitement des données. Il faudrait donc renforcer la robustesse de cette fonction pour permettre une lecture correcte des données et une génération fonctionnelle des fichiers XML.
- Révision du système de comptage des fichiers générés :
- Une autre anomalie observée concerne le comptage des fichiers générés, qui s'affiche sur chaque étape du programme. Ce comptage peut s'avérer incorrect dans certains contextes (en général, le comptage est bien inférieurs aux fichiers effectivement générés). Une correction est à apporter pour s’assurer que le nombre total affiché corresponde précisément aux fichiers effectivement produits.
5. Bilan personnel
Ma relation avec mon maître de stage a été assez positive : je me suis bien intégré et il s’est montré disponible et à l’écoute tout au long de mon stage. J’ai pu poser toutes les questions nécessaires, ce qui m’a permis de progresser efficacement dans le développement de l’application. Même si quelques désaccords ont pu émerger, notamment sur certains aspects techniques de mon code, la communication est toujours restée professionnelle et constructive.
J’ai également eu l’opportunité de travailler de manière autonome sur le projet, ce qui m’a permis de développer mes compétences en gestion de projet et en développement web. Ce stage m’a offert l’occasion d’approfondir mes connaissances en PHP, en découvrant de nouvelles façons d’organiser mon code, même si certains aspects techniques restent encore à perfectionner, comme évoqué dans mes axes d'amélioration. Par ailleurs, j’ai pu mettre en pratique mes connaissances en SASS, une compétence que j'apprends sur mon temps personnel, ce qui m’a aidé à personnaliser Bootstrap de manière plus avancée – une autre compétence travaillée cette année.
Ce stage m’a donc été très bénéfique : il m’a permis de consolider mes acquis et de continuer à progresser sur des compétences en cours d’apprentissage, tout en découvrant un environnement professionnel différent du cadre universitaire. Contrairement à mes projets universitaires où j’occupe souvent un double rôle de “directeur” et de développeur, j’ai ici endossé exclusivement le rôle de développeur. Ce cadre plus restreint m’a aidé à mieux canaliser mon travail, à éviter de m’éparpiller, et à gagner en rigueur, notamment dans ma gestion des fonctionnalités (j’ai tendance à vouloir passer trop vite d’une idée à une autre, ce que ce cadre m’a permis de mieux maîtriser).